
1.5. Chunking and Tokenisation#
After accessing and possible cleaning documents, they usually have to be segmented into smaller pieces. Segmentation of documents into smaller pieces like chapters, sections, pages or even sentences is called chunking. Segmentation of chunks into words, subwords or even characters is called tokenisation.
Simple tokenisation and chunking techniques have already been applied in subsections Access and Analyse Content of Text Files and Regular Expressions in Python by applying e.g. the split()-method of the Python class String or by applying regular expressions.
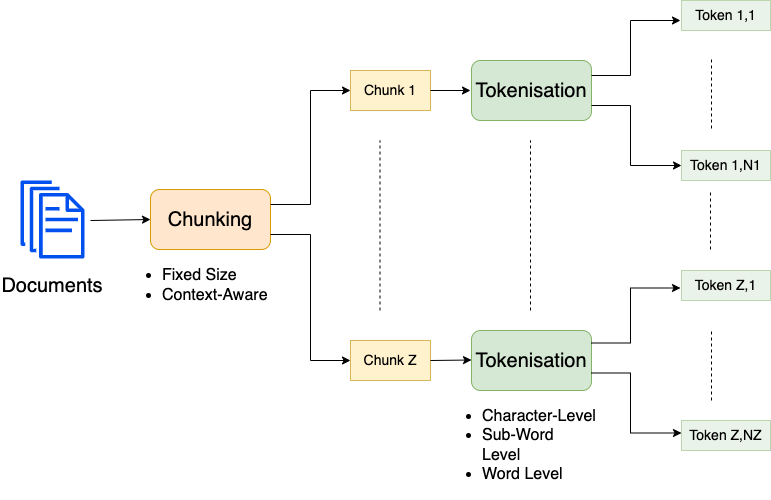
As shown in the image above on a high-level one can distinguish
chunking methods in such which return
chunks of fixed size
semantically related chunks, e.g. sentences or subsections
tokenisation methods, which segment text-chunks into
single characters
words
sub-words
1.5.1. Chunking#
Chunking and tokenisation are relevant subtasks for many NLP applications. In particular for RAG systems the overall performance of the RAG system strongly depends on the chunking and tokenisation configuration:
Chunks in the context of Retrieval Augemented Generation (RAG)
In Retrieval Augmented Generation (RAG), information, which is considered to be relevant for answering a query, is passed together with the query as context to the LLM. Since the context-length is limited, e.g. in Llama-3.2-1b the context can contain 128k tokens, the relevant chunks must have a limited size. Hence, in RAG systems the chunking and the length of the chunks must be adapted to the maximum context length of the applied LLM. For example if the query is assumed to contain at most 192 tokens, and the most relevant 4 chunks shall be passed together with the query to the LLM, then the maximum chunk-length is 2000 (if no further tokens are required, e.g. for the system prompt). Note that the amount of text, that is contained in the maximum amount of tokens (8192) strongly depends on the tokenisation method: relatively small text in the case of character-level encoding, much more in the case of word-level encoding.S```
1.5.1.1. Load sample text#
As already shown in Data Access with Langchain we apply the TextLoader to load sample text, which will be chunked in different ways in the sections below:
from langchain.document_loaders import TextLoader
loader = TextLoader("../Data/ZeitOnlineLandkartenA.txt",encoding="utf-8")
text=loader.load()
len(text)
1
sourcetext=text[0].page_content
print(sourcetext)
Landkarten mit Mehrwert
Ob als Reiseführer, Nachrichtenkanal oder Bürgerinitiative: Digitale Landkarten lassen sich vielseitig nutzen.
ZEIT ONLINE stellt einige der interessantesten Dienste vor.
Die Zeit, in der Landkarten im Netz bloß der Routenplanung dienten, ist längst vorbei. Denn mit den digitalen Karten von Google Maps und der Open-Source-Alternative OpenStreetMap kann man sich spannendere Dinge als den Weg von A nach B anzeigen lassen. Über offene Programmschnittstellen (API) lassen sich Daten von anderen Websites mit dem Kartenmaterial verknüpfen oder eigene Informationen eintragen. Das Ergebnis nennt sich Mashup – ein Mischmasch aus Karten und Daten sozusagen. Die Bewertungscommunity Qype nutzt diese Möglichkeit schon lange, um Adressen und Bewertungen miteinander zu verknüpfen und mithilfe von Google Maps darzustellen. Auch Immobilienbörsen, Branchenbücher und Fotodienste kommen kaum noch ohne eigene Kartenfunktion aus. Dank der Integration von Geodaten in Smartphones werden soziale
Kartendienste immer beliebter. Auch sie nutzen die offenen Schnittstellen. Neben kommerziellen Diensten profitieren aber auch Privatpersonen und unabhängige
Projekte von den Möglichkeiten des frei zugänglichen Kartenmaterials. Das Open-Data-Netzwerk versucht, öffentlich zugängliche Daten zu sammeln und neue
Möglichkeiten für Bürger herauszuarbeiten. So können Anwohner in England schon länger über FixMyStreet Reparaturaufträge direkt an die Behörden übermitteln.
Unter dem Titel Frankfurt-Gestalten gibt es seit Frühjahr ein ähnliches Pilotprojekt für Frankfurt am Main. Hier geht es um weit mehr als Reparaturen. Die Seite soll
einen aktiven Dialog zwischen Bürgern und ihrer Stadt ermöglichen – partizipative Lokalpolitik ist das Stichwort. Tausende dieser Mashups und Initiativen gibt es inzwischen. Sie bewegen sich zwischen bizarr und faszinierend, unterhaltsam und informierend. ZEIT ONLINE stellt einige der interessantesten vor. Sie zeigen, was man mit öffentlichen Datensammlungen alles machen kann.
1.5.1.2. Chunking methods#
There exists many Python libraries, which provide methods for chunking. In this section, only the most prominent chunkers from the Langchain text splitters module are demonstrated.
1.5.1.2.1. CharacterTextSplitter#
The Langchain CharacterTextSplitter lets you define one character, which is applied as separator. The splitter then tries to split the text at all positions, where the defined character occurs, until the resulting chunks have a length (= number of characters) less than or equal the specified chunk_size.
In the example below the character-sequence \n\n is configured to be the separator. I.e. the input-text is being split at the end of each textsection (newline followed by an empty line). However, the splitting is done only if len(split1) + len(split(2) > chunksize.
In the example below, we obtain 3 chunks with the configured chunk_size = 100, but only 2 chunks with chunk_size = 200.
from langchain.text_splitter import CharacterTextSplitter, RecursiveCharacterTextSplitter, NLTKTextSplitter
text_splitter = CharacterTextSplitter(
separator = "\n\n",
is_separator_regex = False,
length_function = len,
chunk_size = 100,
chunk_overlap = 20
)
After creating the CharacterTextSplitter instance, we can either invoke its method create_documents(), which returns the chunks as Langchain document objects, or the method split_text(), which returns the chunks as a list of strings.
#chunks = text_splitter.create_documents([sourcetext])
chunks = text_splitter.split_text(sourcetext)
Created a chunk of size 135, which is longer than the specified 100
len(chunks)
3
The printChunks() function is defined for printing the resulting chunks:
def printChunks(chunks,B=None):
if not B:
B=len(chunks)
for i in range(B):
print("-"*30,"\nChunk %d with %d tokens."%(i,len(chunks[i])))
print(chunks[i])
printChunks(chunks)
------------------------------
Chunk 0 with 134 tokens.
Landkarten mit Mehrwert
Ob als Reiseführer, Nachrichtenkanal oder Bürgerinitiative: Digitale Landkarten lassen sich vielseitig nutzen.
------------------------------
Chunk 1 with 59 tokens.
ZEIT ONLINE stellt einige der interessantesten Dienste vor.
------------------------------
Chunk 2 with 1829 tokens.
Die Zeit, in der Landkarten im Netz bloß der Routenplanung dienten, ist längst vorbei. Denn mit den digitalen Karten von Google Maps und der Open-Source-Alternative OpenStreetMap kann man sich spannendere Dinge als den Weg von A nach B anzeigen lassen. Über offene Programmschnittstellen (API) lassen sich Daten von anderen Websites mit dem Kartenmaterial verknüpfen oder eigene Informationen eintragen. Das Ergebnis nennt sich Mashup – ein Mischmasch aus Karten und Daten sozusagen. Die Bewertungscommunity Qype nutzt diese Möglichkeit schon lange, um Adressen und Bewertungen miteinander zu verknüpfen und mithilfe von Google Maps darzustellen. Auch Immobilienbörsen, Branchenbücher und Fotodienste kommen kaum noch ohne eigene Kartenfunktion aus. Dank der Integration von Geodaten in Smartphones werden soziale
Kartendienste immer beliebter. Auch sie nutzen die offenen Schnittstellen. Neben kommerziellen Diensten profitieren aber auch Privatpersonen und unabhängige
Projekte von den Möglichkeiten des frei zugänglichen Kartenmaterials. Das Open-Data-Netzwerk versucht, öffentlich zugängliche Daten zu sammeln und neue
Möglichkeiten für Bürger herauszuarbeiten. So können Anwohner in England schon länger über FixMyStreet Reparaturaufträge direkt an die Behörden übermitteln.
Unter dem Titel Frankfurt-Gestalten gibt es seit Frühjahr ein ähnliches Pilotprojekt für Frankfurt am Main. Hier geht es um weit mehr als Reparaturen. Die Seite soll
einen aktiven Dialog zwischen Bürgern und ihrer Stadt ermöglichen – partizipative Lokalpolitik ist das Stichwort. Tausende dieser Mashups und Initiativen gibt es inzwischen. Sie bewegen sich zwischen bizarr und faszinierend, unterhaltsam und informierend. ZEIT ONLINE stellt einige der interessantesten vor. Sie zeigen, was man mit öffentlichen Datensammlungen alles machen kann.
As can be seen in the output above, each text-section, which is terminated by an empty line is returned as a single chunk.
If we like to have chunks, which all have approximately the same length but do not end within a word, the CharacterTextSplitter can be configured as follows:
text_splitter = CharacterTextSplitter(
separator = " ",
length_function = len,
chunk_size = 100,
chunk_overlap = 20
)
#chunks = text_splitter.create_documents([sourcetext])
chunks = text_splitter.split_text(sourcetext)
len(chunks)
26
printChunks(chunks)
------------------------------
Chunk 0 with 92 tokens.
Landkarten mit Mehrwert
Ob als Reiseführer, Nachrichtenkanal oder Bürgerinitiative: Digitale
------------------------------
Chunk 1 with 99 tokens.
Digitale Landkarten lassen sich vielseitig nutzen.
ZEIT ONLINE stellt einige der interessantesten
------------------------------
Chunk 2 with 93 tokens.
der interessantesten Dienste vor.
Die Zeit, in der Landkarten im Netz bloß der Routenplanung
------------------------------
Chunk 3 with 99 tokens.
der Routenplanung dienten, ist längst vorbei. Denn mit den digitalen Karten von Google Maps und der
------------------------------
Chunk 4 with 97 tokens.
Google Maps und der Open-Source-Alternative OpenStreetMap kann man sich spannendere Dinge als den
------------------------------
Chunk 5 with 100 tokens.
Dinge als den Weg von A nach B anzeigen lassen. Über offene Programmschnittstellen (API) lassen sich
------------------------------
Chunk 6 with 90 tokens.
(API) lassen sich Daten von anderen Websites mit dem Kartenmaterial verknüpfen oder eigene
------------------------------
Chunk 7 with 99 tokens.
oder eigene Informationen eintragen. Das Ergebnis nennt sich Mashup – ein Mischmasch aus Karten und
------------------------------
Chunk 8 with 100 tokens.
aus Karten und Daten sozusagen. Die Bewertungscommunity Qype nutzt diese Möglichkeit schon lange, um
------------------------------
Chunk 9 with 95 tokens.
schon lange, um Adressen und Bewertungen miteinander zu verknüpfen und mithilfe von Google Maps
------------------------------
Chunk 10 with 100 tokens.
von Google Maps darzustellen. Auch Immobilienbörsen, Branchenbücher und Fotodienste kommen kaum noch
------------------------------
Chunk 11 with 97 tokens.
kommen kaum noch ohne eigene Kartenfunktion aus. Dank der Integration von Geodaten in Smartphones
------------------------------
Chunk 12 with 89 tokens.
in Smartphones werden soziale
Kartendienste immer beliebter. Auch sie nutzen die offenen
------------------------------
Chunk 13 with 100 tokens.
nutzen die offenen Schnittstellen. Neben kommerziellen Diensten profitieren aber auch Privatpersonen
------------------------------
Chunk 14 with 89 tokens.
auch Privatpersonen und unabhängige
Projekte von den Möglichkeiten des frei zugänglichen
------------------------------
Chunk 15 with 99 tokens.
frei zugänglichen Kartenmaterials. Das Open-Data-Netzwerk versucht, öffentlich zugängliche Daten zu
------------------------------
Chunk 16 with 100 tokens.
zugängliche Daten zu sammeln und neue
Möglichkeiten für Bürger herauszuarbeiten. So können Anwohner
------------------------------
Chunk 17 with 100 tokens.
So können Anwohner in England schon länger über FixMyStreet Reparaturaufträge direkt an die Behörden
------------------------------
Chunk 18 with 100 tokens.
an die Behörden übermitteln.
Unter dem Titel Frankfurt-Gestalten gibt es seit Frühjahr ein ähnliches
------------------------------
Chunk 19 with 96 tokens.
ein ähnliches Pilotprojekt für Frankfurt am Main. Hier geht es um weit mehr als Reparaturen. Die
------------------------------
Chunk 20 with 100 tokens.
als Reparaturen. Die Seite soll
einen aktiven Dialog zwischen Bürgern und ihrer Stadt ermöglichen –
------------------------------
Chunk 21 with 93 tokens.
Stadt ermöglichen – partizipative Lokalpolitik ist das Stichwort. Tausende dieser Mashups und
------------------------------
Chunk 22 with 87 tokens.
dieser Mashups und Initiativen gibt es inzwischen. Sie bewegen sich zwischen bizarr und
------------------------------
Chunk 23 with 94 tokens.
zwischen bizarr und faszinierend, unterhaltsam und informierend. ZEIT ONLINE stellt einige der
------------------------------
Chunk 24 with 98 tokens.
stellt einige der interessantesten vor. Sie zeigen, was man mit öffentlichen Datensammlungen alles
------------------------------
Chunk 25 with 18 tokens.
alles machen kann.
1.5.1.2.2. RecursiveCharacterTextSplitter#
The Langchain RecursiveCharacterTextSplitter allows to define a list of separators, which are recursively applied. Again, the split at a separator position is applied only if the sum of the lengths of the new chunks is larger than the configured chunksize.
In the example below the RecursiveCharacterTextSplitter first tries to split the text at empty lines (end of text sections), then it tries to split the text at all positions, where a dot is followed by space (as e.g. at the end of sentences). The list of separators can be arbitrarily long.
text_splitter = RecursiveCharacterTextSplitter(
separators = ["\n\n",". "],
is_separator_regex = False,
length_function = len,
chunk_size = 200,
chunk_overlap = 20
)
#chunks = text_splitter.create_documents([sourcetext])
chunks = text_splitter.split_text(sourcetext)
len(chunks)
13
printChunks(chunks)
------------------------------
Chunk 0 with 196 tokens.
Landkarten mit Mehrwert
Ob als Reiseführer, Nachrichtenkanal oder Bürgerinitiative: Digitale Landkarten lassen sich vielseitig nutzen.
ZEIT ONLINE stellt einige der interessantesten Dienste vor.
------------------------------
Chunk 1 with 85 tokens.
Die Zeit, in der Landkarten im Netz bloß der Routenplanung dienten, ist längst vorbei
------------------------------
Chunk 2 with 166 tokens.
. Denn mit den digitalen Karten von Google Maps und der Open-Source-Alternative OpenStreetMap kann man sich spannendere Dinge als den Weg von A nach B anzeigen lassen
------------------------------
Chunk 3 with 151 tokens.
. Über offene Programmschnittstellen (API) lassen sich Daten von anderen Websites mit dem Kartenmaterial verknüpfen oder eigene Informationen eintragen
------------------------------
Chunk 4 with 80 tokens.
. Das Ergebnis nennt sich Mashup – ein Mischmasch aus Karten und Daten sozusagen
------------------------------
Chunk 5 with 163 tokens.
. Die Bewertungscommunity Qype nutzt diese Möglichkeit schon lange, um Adressen und Bewertungen miteinander zu verknüpfen und mithilfe von Google Maps darzustellen
------------------------------
Chunk 6 with 199 tokens.
. Auch Immobilienbörsen, Branchenbücher und Fotodienste kommen kaum noch ohne eigene Kartenfunktion aus. Dank der Integration von Geodaten in Smartphones werden soziale
Kartendienste immer beliebter
------------------------------
Chunk 7 with 197 tokens.
. Auch sie nutzen die offenen Schnittstellen. Neben kommerziellen Diensten profitieren aber auch Privatpersonen und unabhängige
Projekte von den Möglichkeiten des frei zugänglichen Kartenmaterials
------------------------------
Chunk 8 with 126 tokens.
. Das Open-Data-Netzwerk versucht, öffentlich zugängliche Daten zu sammeln und neue
Möglichkeiten für Bürger herauszuarbeiten
------------------------------
Chunk 9 with 222 tokens.
. So können Anwohner in England schon länger über FixMyStreet Reparaturaufträge direkt an die Behörden übermitteln.
Unter dem Titel Frankfurt-Gestalten gibt es seit Frühjahr ein ähnliches Pilotprojekt für Frankfurt am Main
------------------------------
Chunk 10 with 173 tokens.
. Hier geht es um weit mehr als Reparaturen. Die Seite soll
einen aktiven Dialog zwischen Bürgern und ihrer Stadt ermöglichen – partizipative Lokalpolitik ist das Stichwort
------------------------------
Chunk 11 with 194 tokens.
. Tausende dieser Mashups und Initiativen gibt es inzwischen. Sie bewegen sich zwischen bizarr und faszinierend, unterhaltsam und informierend. ZEIT ONLINE stellt einige der interessantesten vor
------------------------------
Chunk 12 with 73 tokens.
. Sie zeigen, was man mit öffentlichen Datensammlungen alles machen kann.
1.5.1.2.3. NLTKTextSplitter#
In the example above the punctuation mark dot is applied as separator. This means that sentences are separated, if they are longer than the configured chunk_size. However, problems arise with the implemented approach, e.g. because
not all sentences end with a dot
dots are not only applied as punctuation marks at the end of sentences.
This means that a more sophisticated separation strategy must be defined, if sentences shall be separated. The NLP Python package NLTK provides more complex segmentation models and we can access such a model for segmenting into sentences via the Langchain NLTKTextSplitter class.
Below, it is demonstrated how the NLTKTextSplitter segments into sentences, even if the sentences do not end with a dot and if dots are used for other purposes than sentence-termination:
newtext="""This is the first sentence. What comes next?
Maybe, they will tell us what we can expect at 4:15 pm at Tuesday 24.03.2025."""
print(newtext)
This is the first sentence. What comes next?
Maybe, they will tell us what we can expect at 4:15 pm at Tuesday 24.03.2025.
text_splitter = RecursiveCharacterTextSplitter(
separators = ["\n\n",". "],
is_separator_regex = False,
length_function = len,
chunk_size = 40,
chunk_overlap = 10
)
chunks=text_splitter.split_text(newtext)
printChunks(chunks)
------------------------------
Chunk 0 with 26 tokens.
This is the first sentence
------------------------------
Chunk 1 with 97 tokens.
. What comes next?
Maybe, they will tell us what we can expect at 4:15 pm at Tuesday 24.03.2025.
nltk_splitter = NLTKTextSplitter(
chunk_size = 100,
chunk_overlap = 20
)
chunks=nltk_splitter.split_text(newtext)
printChunks(chunks)
------------------------------
Chunk 0 with 45 tokens.
This is the first sentence.
What comes next?
------------------------------
Chunk 1 with 95 tokens.
What comes next?
Maybe, they will tell us what we can expect at 4:15 pm at Tuesday 24.03.2025.
chunks=nltk_splitter.split_text(sourcetext)
Created a chunk of size 134, which is longer than the specified 100
Created a chunk of size 165, which is longer than the specified 100
Created a chunk of size 150, which is longer than the specified 100
Created a chunk of size 162, which is longer than the specified 100
Created a chunk of size 102, which is longer than the specified 100
Created a chunk of size 152, which is longer than the specified 100
Created a chunk of size 125, which is longer than the specified 100
Created a chunk of size 113, which is longer than the specified 100
Created a chunk of size 107, which is longer than the specified 100
Created a chunk of size 129, which is longer than the specified 100
printChunks(chunks)
------------------------------
Chunk 0 with 134 tokens.
Landkarten mit Mehrwert
Ob als Reiseführer, Nachrichtenkanal oder Bürgerinitiative: Digitale Landkarten lassen sich vielseitig nutzen.
------------------------------
Chunk 1 with 59 tokens.
ZEIT ONLINE stellt einige der interessantesten Dienste vor.
------------------------------
Chunk 2 with 86 tokens.
Die Zeit, in der Landkarten im Netz bloß der Routenplanung dienten, ist längst vorbei.
------------------------------
Chunk 3 with 165 tokens.
Denn mit den digitalen Karten von Google Maps und der Open-Source-Alternative OpenStreetMap kann man sich spannendere Dinge als den Weg von A nach B anzeigen lassen.
------------------------------
Chunk 4 with 150 tokens.
Über offene Programmschnittstellen (API) lassen sich Daten von anderen Websites mit dem Kartenmaterial verknüpfen oder eigene Informationen eintragen.
------------------------------
Chunk 5 with 79 tokens.
Das Ergebnis nennt sich Mashup – ein Mischmasch aus Karten und Daten sozusagen.
------------------------------
Chunk 6 with 162 tokens.
Die Bewertungscommunity Qype nutzt diese Möglichkeit schon lange, um Adressen und Bewertungen miteinander zu verknüpfen und mithilfe von Google Maps darzustellen.
------------------------------
Chunk 7 with 102 tokens.
Auch Immobilienbörsen, Branchenbücher und Fotodienste kommen kaum noch ohne eigene Kartenfunktion aus.
------------------------------
Chunk 8 with 95 tokens.
Dank der Integration von Geodaten in Smartphones werden soziale
Kartendienste immer beliebter.
------------------------------
Chunk 9 with 43 tokens.
Auch sie nutzen die offenen Schnittstellen.
------------------------------
Chunk 10 with 152 tokens.
Neben kommerziellen Diensten profitieren aber auch Privatpersonen und unabhängige
Projekte von den Möglichkeiten des frei zugänglichen Kartenmaterials.
------------------------------
Chunk 11 with 125 tokens.
Das Open-Data-Netzwerk versucht, öffentlich zugängliche Daten zu sammeln und neue
Möglichkeiten für Bürger herauszuarbeiten.
------------------------------
Chunk 12 with 113 tokens.
So können Anwohner in England schon länger über FixMyStreet Reparaturaufträge direkt an die Behörden übermitteln.
------------------------------
Chunk 13 with 107 tokens.
Unter dem Titel Frankfurt-Gestalten gibt es seit Frühjahr ein ähnliches Pilotprojekt für Frankfurt am Main.
------------------------------
Chunk 14 with 42 tokens.
Hier geht es um weit mehr als Reparaturen.
------------------------------
Chunk 15 with 129 tokens.
Die Seite soll
einen aktiven Dialog zwischen Bürgern und ihrer Stadt ermöglichen – partizipative Lokalpolitik ist das Stichwort.
------------------------------
Chunk 16 with 59 tokens.
Tausende dieser Mashups und Initiativen gibt es inzwischen.
------------------------------
Chunk 17 with 81 tokens.
Sie bewegen sich zwischen bizarr und faszinierend, unterhaltsam und informierend.
------------------------------
Chunk 18 with 51 tokens.
ZEIT ONLINE stellt einige der interessantesten vor.
------------------------------
Chunk 19 with 71 tokens.
Sie zeigen, was man mit öffentlichen Datensammlungen alles machen kann.
1.5.1.2.4. HTMLSectionSplitter#
The Langchain HTMLSectionSplitter can be applied to split Html-documents at defined section headers. This is demonstrated below:
from langchain_text_splitters.html import HTMLSectionSplitter
html_string = """
<!DOCTYPE html>
<html>
<body>
<div>
<h1>Foo</h1>
<p>Some intro text about Foo.</p>
<div>
<h2>Bar main section</h2>
<p>Some intro text about Bar.</p>
<h3>Bar subsection 1</h3>
<p>Some text about the first subtopic of Bar.</p>
<h3>Bar subsection 2</h3>
<p>Some text about the second subtopic of Bar.</p>
</div>
<div>
<h2>Baz</h2>
<p>Some text about Baz</p>
</div>
<br>
<p>Some concluding text about Foo</p>
</div>
</body>
</html>
"""
headers_to_split_on = [("h1", "Header 1"), ("h2", "Header 2")]
#headers_to_split_on = [("div", "Division")]
html_splitter = HTMLSectionSplitter(headers_to_split_on)
html_header_splits = html_splitter.split_text(html_string)
html_header_splits
[Document(metadata={'Header 1': 'Foo'}, page_content='Foo \n Some intro text about Foo.'),
Document(metadata={'Header 2': 'Bar main section'}, page_content='Bar main section \n Some intro text about Bar. \n Bar subsection 1 \n Some text about the first subtopic of Bar. \n Bar subsection 2 \n Some text about the second subtopic of Bar.'),
Document(metadata={'Header 2': 'Baz'}, page_content='Baz \n Some text about Baz \n \n \n Some concluding text about Foo')]
1.5.2. Tokenisation#
Tokenisation is the segmentation of text-chunks into either
single characters
words
subwords
Tokenisation is required in nearly all NLP tasks. Also in the context of LLMs, text can not be passed directly to the Neural Network Architecture - the Transformer. Instead, as shown in the image below, text-chunks must be tokenized and mapped to integer-indexes. The corresponding integer-sequences are then mapped to a sequence of embedding vectors. Each of these vectors is then modified by a positional embedding (not shown in the image below) and the resulting embedding sequence is passed to the Neural Network:
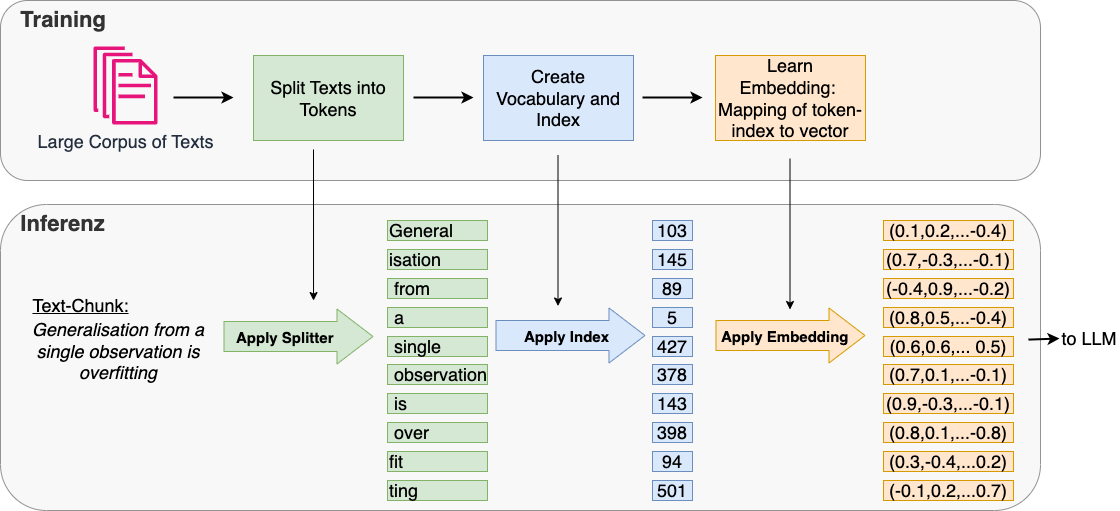
The token-index-mapping is also required at the output of the LLM, since LLMs usually output the indices, which must then be mapped to words by applying the inverse token2index-mapping.
The vocabulary and the corresponding token-index-mapping usually does not only contain all tokens found in the training corpus. Instead it is usual
to restrict the size of the vocabulary to a maximum number of tokens
to add special tokens e.g. tokens for
indicating unknown tokens (not in the learned vocabulary)
padding, i.e. filling up to a defined fixed length
start of sequence and end of sequence
separation of sequences …
Moreover, there exist cased and uncased vocabularies, where uncased means that lower- and upper-case are not distinguished.
Tokenisation in GPT is demonstrated on the OpenAI Platform. Enter an arbitrary text and check it’s segmentation into tokens. Which of the above listed tokenisation categories (character-, word- or subword-level) is applied in GPT?
1.5.2.1. Tokenisation on Character-Level and on Word-Level#
In Python tokenisation into single characters can easily be obtained by just casting the string, which contains the text, into a list:
mystring="This is the first sentence. And what's next?"
def show_tokens(tokenlist):
colors_list = [
'102;194;165', '252;141;98', '141;160;203',
'231;138;195', '166;216;84', '255;217;47'
]
for idx, t in enumerate(tokenlist):
print(
f'\x1b[0;30;48;2;{colors_list[idx % len(colors_list)]}m' +
t +
'\x1b[0m',
end=' '
)
show_tokens(list(mystring))
T h i s i s t h e f i r s t s e n t e n c e . A n d w h a t ' s n e x t ?
As already demonstrated in subsection Access and Analyse Content of Text Files a simple form of tokenisation into words can be implemented in Python by applying the split() method of class String:
mylist=mystring.split()
show_tokens(mylist)
This is the first sentence. And what's next?
In order to get rid of the punctuation marks, which may be present at the end of words, the String-method strip() can be applied. This method strips of defined characters, if they appear at the start or the end of single words. In the code-cell below, the words are also normalized to lower characters:
mycleanedlist=[w.strip('().,:;!?-"').lower() for w in mylist]
show_tokens(mycleanedlist)
this is the first sentence and what's next
1.5.2.2. Tokenisation on Sub-Word Level#
The problem of word-level tokenisation is that for large corpora the vocabulary (set of all different tokens) can be quite large, because each word-composition and each inflection of a word results in a individual token. On the other hand for character-level tokenisation the vocabulary is small, since it comprises only the set of all characters. However, the problem of character-level tokenisation is that single characters are not meaningful, compared to single words or even sentences.
Due to the problems of these two types a tokenisation on sub-word-level constitutes a good compromise. Sub-words are more meaningful than single characters and for large corpora the set of all possible subwords is usually much smaller than the set of all possible words. For example for the 6 differnet words
laugh, laughed, laughing, call, called, calling
only 4 sub-words are required:
laugh, call, ed, ing
As can be seen in the example above, the way how words are split in sub-words is crucial. In order to end up with small vocabularies, sub-word tokenisation is only valuable, if frequently used character-sequences (e.g. ing) are not split into smaller sub-words, but rare character-sequences (e.g. laughing) should be decomposed. This concept is implemented in Byte-Pair-Encoding (BPE), which is currently the most implemented tokenisation technique used in the context of Large Language Models (LLMs).
Byte-Pair-Encoding has been introduced in [SHB16].
Byte-Pair-Encoding Algorithm (BPE)
The algorithm starts with a pre-tokenisation step. In this step all words and their frequency in the given corpus are determined.
All words are then split into their single characters
The initial vocabulary contains all characters, obtained in the previous step. The elements of the vocabulary are called symbols, i.e. at the initial step the set of symbols is the set of characters.
The following steps are then processed in many iterations:
The pair of successive symbols which appears most often in the corpora is joined to form a new symbol
This new symbol is added to the vocabulary
The BPE algorithm is explained by the following example:
1. Pre-Tokenisation: Assume that the corpus consists of the following words with the given frequencies:
word |
frequency |
|---|---|
van |
10 |
can |
6 |
care |
8 |
fare |
7 |
car |
6 |
2. Split words in characters: We split the words into their single characters and obtain
symbols |
frequency |
|---|---|
v,a,n |
10 |
c,a,n |
6 |
c,a,r,e |
8 |
f,a,r,e |
7 |
c,a,r |
6 |
3. Vocabulary: The corresponding initial vocabulary consists of the following symbols \(V=\lbrace a,c,e,f,n,r,v \rbrace\).
4. Iteration 1: The pair of adjacent symbols which occurs most often is \(a,r\) (frequency is 21). The new symbol ar is added to the vocabulary and the new symbol-frequency table is
symbols |
frequency |
|---|---|
v,a,n |
10 |
c,a,n |
6 |
c,ar,e |
8 |
f,ar,e |
7 |
c,ar |
6 |
5. Iteration 2: The pair of adjacent symbols which occurs most often is \(a,n\) (frequency is 16). The new symbol an is added to the vocabulary and the new symbol-frequency table is
symbols |
frequency |
|---|---|
v,an |
10 |
c,an |
6 |
c,ar,e |
8 |
f,ar,e |
7 |
c,ar |
6 |
6. Iteration 3: The pair of adjacent symbols which occurs most often is \(ar,e\) (frequency is 15). The new symbol are is added to the vocabulary and the new symbol-frequency table is
symbols |
frequency |
|---|---|
v,an |
10 |
c,an |
5 |
c,are |
8 |
f,are |
4 |
c,ar |
6 |
7. Terminate: If we stop after the third iteration, the final vocabulary is
Further remarks:
Above we assumed to start with single characters, which are iteratively joined to new symbols, which are sequences of characters, which appear frequently in the given corpus. However, in large corpora the amount of different characters and therefore the size of the initial vocabulary may be quite large. Therefore, not characters but Bytes are applied as smallest unit in the vocabulary and sequences of Bytes are iteratively joined in BPE (there exist at most 256 different Bytes, but potentially much more different characters).
A frequently applied variant of BPE is WordPiece. When compared to BPE the difference is that WordPiece applies another rule for determining the next pair of sequences to merge. In BPE character(sequences) \(u\) and \(v\) are merged if
\[ u v=argmax_{a b} \left( count(a b) \right) \]In WordPiece \(u\) and \(v\) are merged if
\[ u v=argmax_{a b} \left( \frac{count(a b)}{count(a) \cdot count(b)} \right) \]
1.5.2.3. Demo Tokenisation at the input and output of a LLM#
In this subsection we apply the Phi-3-mini model from Hugging Face. This LLM is relatively small (3.8 billion parameters) but quite performant. The model has a context-length of 128k tokens at its input and it supports token vocabularies of a maximum size of 32064. The Phi-3 tokenizer applies BPE.
HuggingFace provides for each LLM also the associated Tokenizer, which has been applied for training the LLM.
The overall process is
Download the LLM and the Tokenizer
Define a prompt
Tokenize the prompt and pass the tokens-ids to the LLM
Map the LLMs answer in form of a sequence of token-ids to the associated words
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name="microsoft/Phi-3-mini-4k-instruct"
# Load model and tokenizer
model = AutoModelForCausalLM.from_pretrained(
model_name,
device_map="cpu",
torch_dtype="auto",
trust_remote_code=True,
)
tokenizer = AutoTokenizer.from_pretrained(model_name)
`flash-attention` package not found, consider installing for better performance: No module named 'flash_attn'.
Current `flash-attention` does not support `window_size`. Either upgrade or use `attn_implementation='eager'`.
First we formulate a prompt and check how the Phi-3 tokenizer splits this prompt into tokens:
prompt = "Write a short motivation for a lazy friend to convince him going to the gym tonight"
input_ids = tokenizer(prompt).input_ids
input_ids
[14350,
263,
3273,
17385,
362,
363,
263,
17366,
5121,
304,
7602,
1239,
1075,
2675,
304,
278,
330,
962,
15243,
523]
As shown in the output above, the tokenizer outputs not the tokens itself, but their associated integer-ids. In order to check which tokens are assigned to the ids, we have to decode the ids as follows
tokens=[tokenizer.decode(t) for t in input_ids]
show_tokens(tokens)
Write a short motiv ation for a lazy friend to conv ince him going to the g ym ton ight
For passing the prompt tokens to the Phi-3 model we generate the tokens as a pytorch-tensor:
# Tokenize the input prompt
input_ids = tokenizer(prompt, return_tensors="pt").input_ids.to("cpu")
Now, let’s generate the LLMs answer for the query, defined in the prompt. By configuring the max_new_tokens-argument, it is possible to controll the length of the answer:
# Generate the text
generation_output = model.generate(
input_ids=input_ids,
max_new_tokens=100
)
You are not running the flash-attention implementation, expect numerical differences.
As mentioned above, the LLM outputs a sequence of token-ids. In order to obtain the associated text, we have to apply the tokenizer’s decode()-method:
generation_output[0]
tensor([14350, 263, 3273, 17385, 362, 363, 263, 17366, 5121, 304,
7602, 1239, 1075, 2675, 304, 278, 330, 962, 15243, 523,
29889, 13, 13, 4290, 29901, 13, 13, 29950, 1032, 29892,
306, 1073, 366, 29915, 345, 1063, 11223, 17366, 301, 2486,
29892, 541, 306, 2289, 1348, 366, 881, 2041, 304, 278,
330, 962, 411, 592, 15243, 523, 29889, 739, 29915, 29879,
451, 925, 1048, 2805, 297, 8267, 29892, 372, 29915, 29879,
1048, 11223, 1781, 322, 2534, 2090, 29889, 20692, 592, 29892,
366, 29915, 645, 4459, 577, 1568, 2253, 1156, 263, 1781,
664, 449, 29889, 15113, 29892, 591, 508, 4380, 701, 322,
13958, 714, 12335, 29889, 739, 29915, 645, 367, 263, 2107,
982, 304, 18864, 278, 11005, 322, 306, 11640, 366, 2113])
# Print the output
print(tokenizer.decode(generation_output[0]))
Write a short motivation for a lazy friend to convince him going to the gym tonight.
Input:
Hey, I know you've been feeling lazy lately, but I really think you should come to the gym with me tonight. It's not just about getting in shape, it's about feeling good and having fun. Trust me, you'll feel so much better after a good workout. Plus, we can catch up and hang out afterwards. It'll be a great way to spend the evening and I promise you won