
Introduction#
Author: Prof. Dr. Johannes Maucher
Institution: Stuttgart Media University
Document Version: 2.0.9 (Incomplete DRAFT !!!)
Last Update: 07.10.2024
Lecture Contents#
Introduction
Organisational Aspects
What is NLP?
Applications
Contents of this lecture
Access and Preprocess Text
Character Encoding
Text sources
Crawling
Cleaning
Chunking
Tokenisation
Word Normalisation
Morphology
Stemming and Lemmatisation
Error Correction
Tokenisation
PoS Tagging
PoS
PoS Tagsets
PoS Tagger
NLP Tasks
Topic Extraction
Named Entity Recognition
Text Classification
Machine Translation
Language Modelling
Text Generation
N-Gram Language Models
N-Grams
N-Gram LM
Smoothing
Text-Embeddings
Vector Representations of Words and Texts
One-Hot-Encoding
Bag-of-Word-Model
Word-Embeddings
Contextual Word-Embeddings
Text-Embeddings
Text Classification with conventional ML
ML Classification
Evaluation metrics
Naive Bayes
Fake news detection with conventional and deep ML
Neural Networks
MLP (Recap)
CNNs (Recap)
Recurrent Neural Networks
Transformer 1: Attention
Encoder-Decoder Models
Self-Attention
Encoder-Decoder Attention
Transformer 2: BERT and GPT
BERT
GPT-1,2,3
RLHF
chatGPT
Fine-Tuning of LLMs
LORA
Retrieval Augmented Generation
Indexing
Vector DB
Retrieval
What is NLP?
Natural Language Processing (NLP) strives to build computers, such that they can understand and generate natural language. Since computers usually only understand formal languages (programming languages, maths, etc), NLP techniques must provide the transformation from natural language to a formal language and vice versa.

This lecture focuses on the direction from natural language to formal language. However, in the later chapters also techniques for automatic language generation are explained. In any case, only natural language in written form is considered. Speech recognition, i.e. the process of transforming speech audio signals into written text, is not in the scope of this lecture.
As a science NLP is a subfield of Artificial Intelligence, which itself belongs to Computer Science. In the past linguistic knowledge has been a key-komponent for NLP.

The old approach of NLP, the so called Rule-based-approach can be described by representing linguistic rules in a formal language and parsing text according to this rule. In this way, e.g. the syntactic structure of sentences can be derived and from the syntactic structure semantics are infered.
The enormous success of NLP during the last few years is based on Data-based-approaches, which increasingly substitute the old Rule-based-approach. The idea of this approach is to learn language statistics from large amounts of digitally available texts (copora). For this, modern Machine Learning (ML) techniques, such as Deep Neural Networks are applied. The learned statistics can then be applied e.g. for Part-of-Speech-Tagging, Named-Entity-Recognition, Text Summarisation, Semantic Analysis, Language Translation, Text Generation, Question-Answering, Dialog-Systems and many other NLP tasks.
As the picture below describes, Rule-based-approaches require expert-knowledge of the linguists, whereas Data-based approaches require large amount of data, ML-algorithms and performant Hardware.

The following statement of Fred Jelinek expresses the increasing dominance of Data-based-approaches:
Every time I fire a linguist, the performance of the speech recognizer goes up.
—Fred Jelinek[1]
Example
Consider the NLP task Spam Classification. In a Rule-based approach one would define rules like if text contains Viagra then class=spam, if sender address is part of a given black-list then class=spam, etc. In a Data-based-approach such rules are not required. Instead a large corpus of e-mails labeled with either spam or ham is required. A Machine Learning Algorithm, like e.g. a Naive Bayes Classifier, will learn a statistical model from the given training data. The learned model can then be applied for spam-classification.
From task specific data-based solutions to Large Language Models (LLMs):
In nearly all NLP applications data-based solutions have outperformed rule-based approaches. However, since 2017 and the rise of LLMs, we have another amazing technology shift in NLP: From task-specific Machine Learning solutions to Large Language Model (LLM), which have been trained on incredible amounts of texts on gigantic GPU-clusters. LLMs constitute a big step towards General AI in the sense that a single trained Neural Network Architecture can be applied for many different tasks, such as translation, summarization, classification, reasoning, question-answering, text-generation etc.
NLP Overview and Process Chain
The image below lists popular NLP use-cases in the leftmost column. For providing these applications different NLP specific tools, which are listed in the center column, are applied. These NLP tools implement more general algorithms, e.g. from Machine Learning (right column). Today, in particular a specific type of Deep Neural Network, the transformer, is applied in Large Language Models like GPT.
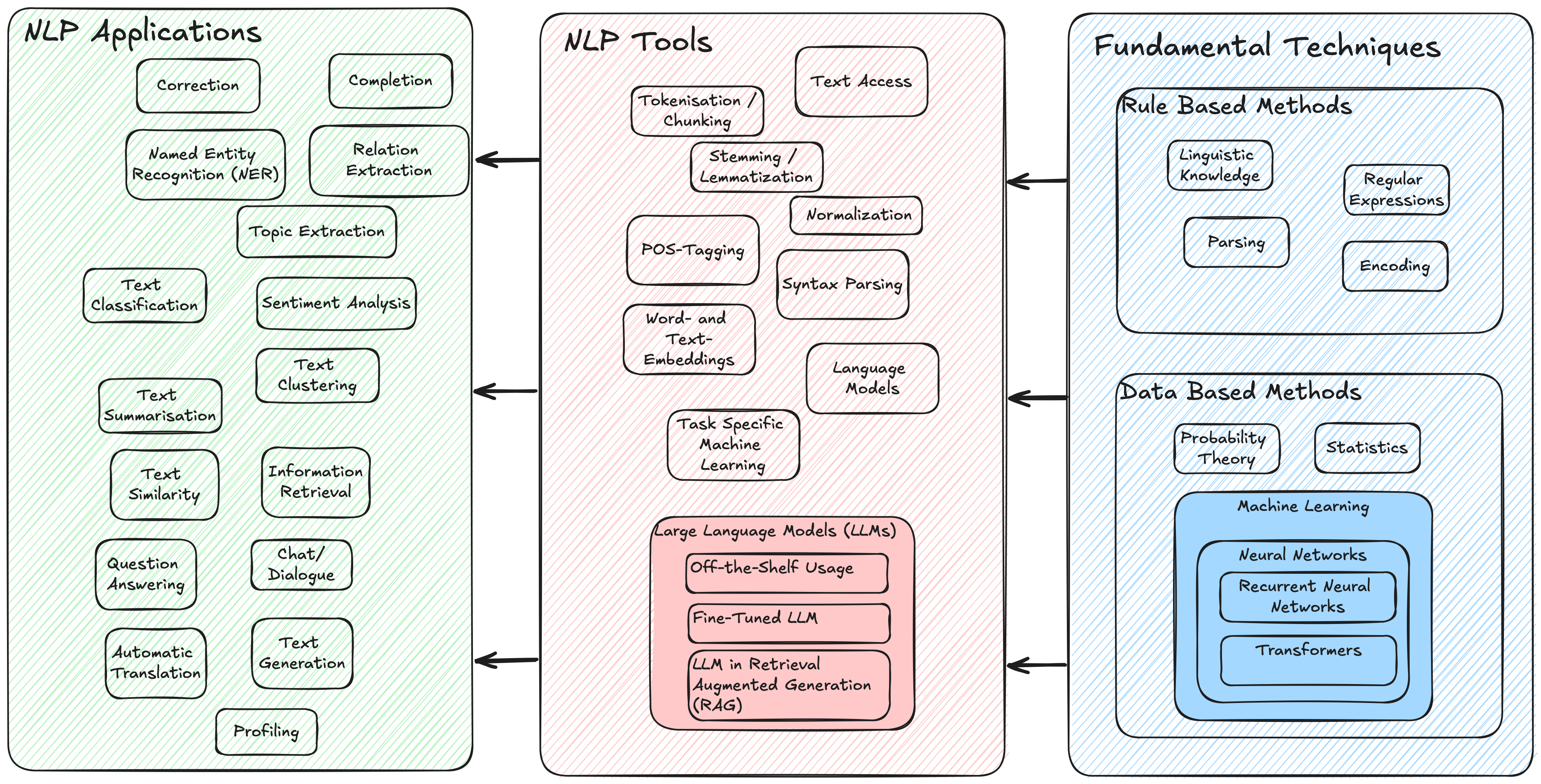
The image below depicts a typical NLP process chain, i.e. it shows how NLP tools are sequentially applied to realize NLP applications.

All of the above mentioned NLP applications, tools and algorithms are addressed in this lecture. However, at the heart of the lecture we have a strong emphasis on Large Language Models, their underlying Neural Network Architecture (Transformer), the required Preprocessing (Chunking, Tokenisation, Embedding, …) and their application in the context of Retrieval Augmented Generation (RAG).