5.2. Implementation of BoWs#
Author: Johannes Maucher
Last update: 01.11.2024
This notebook demonstrates how documents can be described in a vector space model. Applying this type of model
similarities between documents
similarities between documents and a query
can easily be calculated.
5.2.1. Read documents from Newsfeed#
#!pip install feedparser
import feedparser
feed='http://newsfeed.zeit.de/index'
newsliststring=[]
f=feedparser.parse(feed)
for e in f.entries:
text=e.title+"\n"+e.description
newsliststring.append(text)
#print('\n---------------------------')
#print(text)
newsliststring
['Umwelt: Robben in Netzen verendet? Expertin sieht weitere Hinweise\n',
'Ermittlungen: Mann wird auf Straße gefunden - und stirbt zwei Tage später\n',
'Umfragen zur US-Wahl: Wer zieht ins Weiße Haus – Donald Trump oder Kamala Harris?\nDie Kandidaten liegen weiter nah beisammen, doch Trump erlangt die Führung in wichtigen Swing-States. Die Daten zum US-Wahlkampf im täglich aktualisierten Überblick',
'Ampelstreit: Christian Lindner fordert Kehrtwende in Wirtschafts- und Finanzpolitik\nDer Bundesfinanzminister distanziert sich in einem Grundsatzpapier in Teilen von der Ampelregierung. Mit Blick auf den Bundeshaushalt fordert er weitere Einsparungen.',
'3. Fußball-Liga: Wehen Wiesbaden mit Respekt vor Pokal-Schreck Bielefeld\n',
'Hochschulen: Peter Bernshausen ist neuer Kanzler der TU Chemnitz\n',
'Katargate: EU-Staatsanwaltschaft ermittelt gegen hohen Beamten wegen Korruption\nIn der EU laufen Ermittlungen gegen Henrik Hololei. Der estnische EU-Beamte steht unter Verdacht, teure Geschenke aus Katar angenommen zu haben.',
'Zweithöchste Warnstufe: Unwetter erreicht Balearen: Starker Regen auf Mallorca\n',
'Nahostkonflikt: Trügerische Siege\nIsrael hat Irans Macht in der Region stark geschwächt. So dominant wie heute war es noch nie. Doch der Iran könnte aus seiner derzeitigen Schwäche eine Stärke machen.',
'Kriminalität: 18-Jähriger soll mehr als 30 Straftaten begangen haben\n',
'Ukraine-Krieg: Der Winter naht, die Ukraine macht mobil\nDie Ukraine erlebte im Oktober einen der härtesten Monate seit Kriegsbeginn. Jetzt beginnt der Winter. Wie ist die Stimmung? Und wieder Unwetterwarnungen in Spanien',
'Umgang mit der AfD: Senatorin warnt vor AfD-Verbotsverfahren auf Bundesebene\n',
'Hamburgs Gewässer: Die Elbe kann mehr, als nur Schiffe zu tragen\nEin Podcast für mehr Lebensqualität: Hamburg könnte Elbe, Alster und Bille noch besser nutzen. Wo man künftig schwimmen, surfen und flanieren könnte.',
'Klimaschutz: Jugendliche sollen in Klimaräten mitwirken können\n',
'US-Wahlkampf: Liz Cheney warnt nach erneuter Attacke vor Donald Trump\nAuf offener Bühne diskutierte Donald Trump Gewaltfantasien gegen seine parteiinterne Kritikerin Liz Cheney. Die warnt nun vor einem Tyrannen als Präsidenten.']
5.2.2. Tokenisation#
In Keras methods for preprocessing texts are contained in keras.preprocessing.text. From this module, we apply the Tokenizer-class to
transform words to integers, i.e. generating a word-index
represent texts as sequences of integers
represent collections of texts in a Bag-of-Words (BOW)-matrix
from tensorflow.keras.preprocessing.text import Tokenizer
Generate a Tokenizer-object and fit it on the given list of texts:
tokenizer = Tokenizer()
tokenizer.fit_on_texts(newsliststring)
The Tokenizer-class accepts a list of arguments, which can be configured at initialisation of a Tokenizer-object. The default-values are printed below
print("Configured maximum number of words in the vocabulary: ",tokenizer.num_words) #Maximum number of words to regard in the vocabulary
print("Configured filters: ",tokenizer.filters) #characters to ignore in tokenization
print("Map all characters to lower case: ",tokenizer.lower) #Mapping of characters to lower-case
print("Tokenizsation on character level: ",tokenizer.char_level) #whether tokens are words or characters
Configured maximum number of words in the vocabulary: None
Configured filters: !"#$%&()*+,-./:;<=>?@[\]^_`{|}~
Map all characters to lower case: True
Tokenizsation on character level: False
print("Number of documents: ",tokenizer.document_count)
print("Number of words: ",len(tokenizer.word_index))
Number of documents: 15
Number of words: 228
print("Index of words: ",tokenizer.word_index)
Index of words: {'der': 1, 'in': 2, 'die': 3, 'auf': 4, 'und': 5, 'trump': 6, 'vor': 7, 'us': 8, 'donald': 9, 'mit': 10, 'eu': 11, 'gegen': 12, 'könnte': 13, 'mehr': 14, 'als': 15, 'ukraine': 16, 'warnt': 17, 'weitere': 18, 'ermittlungen': 19, 'doch': 20, 'wahlkampf': 21, 'im': 22, 'fordert': 23, 'einem': 24, 'ist': 25, 'aus': 26, 'zu': 27, 'haben': 28, 'macht': 29, 'wie': 30, 'noch': 31, 'winter': 32, 'afd': 33, 'elbe': 34, 'liz': 35, 'cheney': 36, 'umwelt': 37, 'robben': 38, 'netzen': 39, 'verendet': 40, 'expertin': 41, 'sieht': 42, 'hinweise': 43, 'mann': 44, 'wird': 45, 'straße': 46, 'gefunden': 47, 'stirbt': 48, 'zwei': 49, 'tage': 50, 'später': 51, 'umfragen': 52, 'zur': 53, 'wahl': 54, 'wer': 55, 'zieht': 56, 'ins': 57, 'weiße': 58, 'haus': 59, '–': 60, 'oder': 61, 'kamala': 62, 'harris': 63, 'kandidaten': 64, 'liegen': 65, 'weiter': 66, 'nah': 67, 'beisammen': 68, 'erlangt': 69, 'führung': 70, 'wichtigen': 71, 'swing': 72, 'states': 73, 'daten': 74, 'zum': 75, 'täglich': 76, 'aktualisierten': 77, 'überblick': 78, 'ampelstreit': 79, 'christian': 80, 'lindner': 81, 'kehrtwende': 82, 'wirtschafts': 83, 'finanzpolitik': 84, 'bundesfinanzminister': 85, 'distanziert': 86, 'sich': 87, 'grundsatzpapier': 88, 'teilen': 89, 'von': 90, 'ampelregierung': 91, 'blick': 92, 'den': 93, 'bundeshaushalt': 94, 'er': 95, 'einsparungen': 96, '3': 97, 'fußball': 98, 'liga': 99, 'wehen': 100, 'wiesbaden': 101, 'respekt': 102, 'pokal': 103, 'schreck': 104, 'bielefeld': 105, 'hochschulen': 106, 'peter': 107, 'bernshausen': 108, 'neuer': 109, 'kanzler': 110, 'tu': 111, 'chemnitz': 112, 'katargate': 113, 'staatsanwaltschaft': 114, 'ermittelt': 115, 'hohen': 116, 'beamten': 117, 'wegen': 118, 'korruption': 119, 'laufen': 120, 'henrik': 121, 'hololei': 122, 'estnische': 123, 'beamte': 124, 'steht': 125, 'unter': 126, 'verdacht': 127, 'teure': 128, 'geschenke': 129, 'katar': 130, 'angenommen': 131, 'zweithöchste': 132, 'warnstufe': 133, 'unwetter': 134, 'erreicht': 135, 'balearen': 136, 'starker': 137, 'regen': 138, 'mallorca': 139, 'nahostkonflikt': 140, 'trügerische': 141, 'siege': 142, 'israel': 143, 'hat': 144, 'irans': 145, 'region': 146, 'stark': 147, 'geschwächt': 148, 'so': 149, 'dominant': 150, 'heute': 151, 'war': 152, 'es': 153, 'nie': 154, 'iran': 155, 'seiner': 156, 'derzeitigen': 157, 'schwäche': 158, 'eine': 159, 'stärke': 160, 'machen': 161, 'kriminalität': 162, '18': 163, 'jähriger': 164, 'soll': 165, '30': 166, 'straftaten': 167, 'begangen': 168, 'krieg': 169, 'naht': 170, 'mobil': 171, 'erlebte': 172, 'oktober': 173, 'einen': 174, 'härtesten': 175, 'monate': 176, 'seit': 177, 'kriegsbeginn': 178, 'jetzt': 179, 'beginnt': 180, 'stimmung': 181, 'wieder': 182, 'unwetterwarnungen': 183, 'spanien': 184, 'umgang': 185, 'senatorin': 186, 'verbotsverfahren': 187, 'bundesebene': 188, 'hamburgs': 189, 'gewässer': 190, 'kann': 191, 'nur': 192, 'schiffe': 193, 'tragen': 194, 'ein': 195, 'podcast': 196, 'für': 197, 'lebensqualität': 198, 'hamburg': 199, 'alster': 200, 'bille': 201, 'besser': 202, 'nutzen': 203, 'wo': 204, 'man': 205, 'künftig': 206, 'schwimmen': 207, 'surfen': 208, 'flanieren': 209, 'klimaschutz': 210, 'jugendliche': 211, 'sollen': 212, 'klimaräten': 213, 'mitwirken': 214, 'können': 215, 'nach': 216, 'erneuter': 217, 'attacke': 218, 'offener': 219, 'bühne': 220, 'diskutierte': 221, 'gewaltfantasien': 222, 'seine': 223, 'parteiinterne': 224, 'kritikerin': 225, 'nun': 226, 'tyrannen': 227, 'präsidenten': 228}
print("Number of docs, in which word appears: ",tokenizer.word_docs)
Number of docs, in which word appears: defaultdict(<class 'int'>, {'in': 7, 'expertin': 1, 'netzen': 1, 'umwelt': 1, 'sieht': 1, 'weitere': 2, 'verendet': 1, 'hinweise': 1, 'robben': 1, 'mann': 1, 'zwei': 1, 'tage': 1, 'wird': 1, 'und': 4, 'auf': 5, 'ermittlungen': 2, 'später': 1, 'stirbt': 1, 'straße': 1, 'gefunden': 1, 'beisammen': 1, 'donald': 2, 'harris': 1, 'zur': 1, 'umfragen': 1, 'us': 2, 'überblick': 1, 'führung': 1, 'zum': 1, 'weiße': 1, 'liegen': 1, 'haus': 1, 'weiter': 1, 'wahlkampf': 2, 'erlangt': 1, 'nah': 1, 'trump': 2, 'wahl': 1, '–': 1, 'die': 4, 'states': 1, 'aktualisierten': 1, 'wichtigen': 1, 'oder': 1, 'täglich': 1, 'doch': 2, 'kamala': 1, 'wer': 1, 'zieht': 1, 'kandidaten': 1, 'daten': 1, 'ins': 1, 'swing': 1, 'im': 2, 'kehrtwende': 1, 'finanzpolitik': 1, 'ampelregierung': 1, 'christian': 1, 'lindner': 1, 'bundesfinanzminister': 1, 'grundsatzpapier': 1, 'den': 1, 'sich': 1, 'einsparungen': 1, 'mit': 3, 'distanziert': 1, 'der': 6, 'wirtschafts': 1, 'fordert': 1, 'bundeshaushalt': 1, 'teilen': 1, 'von': 1, 'blick': 1, 'ampelstreit': 1, 'er': 1, 'einem': 2, 'schreck': 1, 'respekt': 1, '3': 1, 'pokal': 1, 'liga': 1, 'wehen': 1, 'fußball': 1, 'bielefeld': 1, 'vor': 3, 'wiesbaden': 1, 'kanzler': 1, 'tu': 1, 'hochschulen': 1, 'chemnitz': 1, 'ist': 2, 'neuer': 1, 'peter': 1, 'bernshausen': 1, 'wegen': 1, 'staatsanwaltschaft': 1, 'haben': 2, 'angenommen': 1, 'zu': 2, 'katargate': 1, 'beamten': 1, 'hohen': 1, 'korruption': 1, 'aus': 2, 'unter': 1, 'beamte': 1, 'teure': 1, 'katar': 1, 'gegen': 2, 'eu': 1, 'henrik': 1, 'ermittelt': 1, 'hololei': 1, 'steht': 1, 'laufen': 1, 'estnische': 1, 'geschenke': 1, 'verdacht': 1, 'erreicht': 1, 'regen': 1, 'unwetter': 1, 'warnstufe': 1, 'mallorca': 1, 'balearen': 1, 'zweithöchste': 1, 'starker': 1, 'so': 1, 'nahostkonflikt': 1, 'wie': 2, 'seiner': 1, 'region': 1, 'siege': 1, 'eine': 1, 'israel': 1, 'geschwächt': 1, 'war': 1, 'schwäche': 1, 'macht': 2, 'trügerische': 1, 'noch': 2, 'iran': 1, 'es': 1, 'machen': 1, 'dominant': 1, 'stärke': 1, 'stark': 1, 'irans': 1, 'hat': 1, 'nie': 1, 'könnte': 2, 'heute': 1, 'derzeitigen': 1, '30': 1, 'soll': 1, 'als': 3, 'mehr': 2, 'begangen': 1, 'jähriger': 1, '18': 1, 'straftaten': 1, 'kriminalität': 1, 'naht': 1, 'härtesten': 1, 'jetzt': 1, 'krieg': 1, 'kriegsbeginn': 1, 'seit': 1, 'beginnt': 1, 'erlebte': 1, 'unwetterwarnungen': 1, 'einen': 1, 'monate': 1, 'oktober': 1, 'mobil': 1, 'stimmung': 1, 'winter': 1, 'wieder': 1, 'ukraine': 1, 'spanien': 1, 'umgang': 1, 'senatorin': 1, 'warnt': 2, 'bundesebene': 1, 'afd': 1, 'verbotsverfahren': 1, 'kann': 1, 'nutzen': 1, 'alster': 1, 'schiffe': 1, 'künftig': 1, 'für': 1, 'hamburgs': 1, 'flanieren': 1, 'tragen': 1, 'schwimmen': 1, 'gewässer': 1, 'man': 1, 'bille': 1, 'ein': 1, 'elbe': 1, 'wo': 1, 'lebensqualität': 1, 'surfen': 1, 'nur': 1, 'hamburg': 1, 'besser': 1, 'podcast': 1, 'klimaschutz': 1, 'mitwirken': 1, 'klimaräten': 1, 'sollen': 1, 'jugendliche': 1, 'können': 1, 'nach': 1, 'diskutierte': 1, 'attacke': 1, 'bühne': 1, 'erneuter': 1, 'seine': 1, 'cheney': 1, 'liz': 1, 'kritikerin': 1, 'nun': 1, 'präsidenten': 1, 'gewaltfantasien': 1, 'tyrannen': 1, 'offener': 1, 'parteiinterne': 1})
textSeqs=tokenizer.texts_to_sequences(newsliststring)
for i,ts in enumerate(textSeqs):
print("text %d sequence: "%i,ts)
text 0 sequence: [37, 38, 2, 39, 40, 41, 42, 18, 43]
text 1 sequence: [19, 44, 45, 4, 46, 47, 5, 48, 49, 50, 51]
text 2 sequence: [52, 53, 8, 54, 55, 56, 57, 58, 59, 60, 9, 6, 61, 62, 63, 3, 64, 65, 66, 67, 68, 20, 6, 69, 3, 70, 2, 71, 72, 73, 3, 74, 75, 8, 21, 22, 76, 77, 78]
text 3 sequence: [79, 80, 81, 23, 82, 2, 83, 5, 84, 1, 85, 86, 87, 2, 24, 88, 2, 89, 90, 1, 91, 10, 92, 4, 93, 94, 23, 95, 18, 96]
text 4 sequence: [97, 98, 99, 100, 101, 10, 102, 7, 103, 104, 105]
text 5 sequence: [106, 107, 108, 25, 109, 110, 1, 111, 112]
text 6 sequence: [113, 11, 114, 115, 12, 116, 117, 118, 119, 2, 1, 11, 120, 19, 12, 121, 122, 1, 123, 11, 124, 125, 126, 127, 128, 129, 26, 130, 131, 27, 28]
text 7 sequence: [132, 133, 134, 135, 136, 137, 138, 4, 139]
text 8 sequence: [140, 141, 142, 143, 144, 145, 29, 2, 1, 146, 147, 148, 149, 150, 30, 151, 152, 153, 31, 154, 20, 1, 155, 13, 26, 156, 157, 158, 159, 160, 161]
text 9 sequence: [162, 163, 164, 165, 14, 15, 166, 167, 168, 28]
text 10 sequence: [16, 169, 1, 32, 170, 3, 16, 29, 171, 3, 16, 172, 22, 173, 174, 1, 175, 176, 177, 178, 179, 180, 1, 32, 30, 25, 3, 181, 5, 182, 183, 2, 184]
text 11 sequence: [185, 10, 1, 33, 186, 17, 7, 33, 187, 4, 188]
text 12 sequence: [189, 190, 3, 34, 191, 14, 15, 192, 193, 27, 194, 195, 196, 197, 14, 198, 199, 13, 34, 200, 5, 201, 31, 202, 203, 204, 205, 206, 207, 208, 5, 209, 13]
text 13 sequence: [210, 211, 212, 2, 213, 214, 215]
text 14 sequence: [8, 21, 35, 36, 17, 216, 217, 218, 7, 9, 6, 4, 219, 220, 221, 9, 6, 222, 12, 223, 224, 225, 35, 36, 3, 17, 226, 7, 24, 227, 15, 228]
5.2.3. Represent text-collection as BoW:#
A Bag-Of-Words representation of documents contains \(N\) rows and \(|V|\) columns, where \(N\) is the number of documents in the collection and \(|V|\) is the size of the vocabulary, i.e. the number of different words in the entire document collection.
The entry \(x_{i,j}\) of the BoW-Matrix indicates the relevance of word \(j\) in document \(i\).
In this lecture 3 different types of word-relevance are considered:
Binary BoW: Entry \(x_{i,j}\) is 1 if word \(j\) appears in document \(i\), otherwise 0.
Count-based BoW: Entry \(x_{i,j}\) is the frequency of word \(j\) in document \(i\).
Tf-idf-based BoW: Entry \(x_{i,j}\) is the tf-idf of word \(j\) with respect to document \(i\).
The BoW-representation of texts is a common input to conventional Machine Learning algorithms (not Neural Netorks like CNN and RNN).
5.2.3.1. Binary BoW#
bow_representation_bin = tokenizer.texts_to_matrix(newsliststring)
print(bow_representation_bin.shape)
print(bow_representation_bin)
(15, 229)
[[0. 0. 1. ... 0. 0. 0.]
[0. 0. 0. ... 0. 0. 0.]
[0. 0. 1. ... 0. 0. 0.]
...
[0. 0. 0. ... 0. 0. 0.]
[0. 0. 1. ... 0. 0. 0.]
[0. 0. 0. ... 1. 1. 1.]]
5.2.3.2. Count-based BoW#
Represent text-collection as BoW with word-counts:
bow_representation_count = tokenizer.texts_to_matrix(newsliststring,mode="count")
print(bow_representation_count.shape)
print(bow_representation_count)
(15, 229)
[[0. 0. 1. ... 0. 0. 0.]
[0. 0. 0. ... 0. 0. 0.]
[0. 0. 1. ... 0. 0. 0.]
...
[0. 0. 0. ... 0. 0. 0.]
[0. 0. 1. ... 0. 0. 0.]
[0. 0. 0. ... 1. 1. 1.]]
5.2.3.3. Tf-idf-based BoW#
In the BoW representation above the term frequency (tf) has been applied. This value measures how often the term (word) appears in the document. If document similarity is calculated on such tf-based BoW representation, common words which appear quite often (in many documents) but have low semantic focus, have a strong impact on the similarity-value. In most cases this is a drawback, since similarity should be based on terms with a high semantic focus. Such semantically meaningful words usually appear only in a few documents. The term frequency inversed document frequency measure (tf-idf) does not only count the frequency of a term in a document, but weighs those terms stronger, which occur only in a few documents of the corpus.
bow_representation_idf = tokenizer.texts_to_matrix(newsliststring,mode="tfidf")
print(bow_representation_idf.shape)
print(bow_representation_idf)
(15, 229)
[[0. 0. 1.05605267 ... 0. 0. 0. ]
[0. 0. 0. ... 0. 0. 0. ]
[0. 0. 1.05605267 ... 0. 0. 0. ]
...
[0. 0. 0. ... 0. 0. 0. ]
[0. 0. 1.05605267 ... 0. 0. 0. ]
[0. 0. 0. ... 2.14006616 2.14006616 2.14006616]]
5.2.4. Analyse Similarities#
For each document the most similar document is calculated from the
binary
count
tf-idf BoW-matrix.
from sklearn.metrics.pairwise import cosine_similarity
import numpy as np
def most_similar_rows(bow_representation):
similarities = cosine_similarity(bow_representation)
np.fill_diagonal(similarities, 0) # Ignore self-similarity
most_similar = np.argmax(similarities, axis=1)
return most_similar
most_similar_bin = most_similar_rows(bow_representation_bin)
print("From Binary BoW: \t:",most_similar_bin)
most_similar_count = most_similar_rows(bow_representation_count)
print("From Count BoW: \t:",most_similar_count)
most_similar_idf = most_similar_rows(bow_representation_idf)
print("From tf-idf BoW: \t:",most_similar_idf)
From Binary BoW: : [ 3 3 14 11 11 10 8 11 10 12 8 4 9 0 11]
From Count BoW: : [ 3 7 14 10 11 10 3 1 10 12 3 14 9 3 2]
From tf-idf BoW: : [ 3 3 14 11 11 10 8 11 10 12 8 14 9 3 2]
Plot each document and the corresponding most similar document, calculated from the tf-idf Bow:
for i in range(len(newsliststring)):
print("-"*30)
print("Most similar news to news %d: "%i,most_similar_bin[i],most_similar_count[i],most_similar_idf[i])
print(newsliststring[i])
print(newsliststring[most_similar_idf[i]])
------------------------------
Most similar news to news 0: 3 3 3
Umwelt: Robben in Netzen verendet? Expertin sieht weitere Hinweise
Ampelstreit: Christian Lindner fordert Kehrtwende in Wirtschafts- und Finanzpolitik
Der Bundesfinanzminister distanziert sich in einem Grundsatzpapier in Teilen von der Ampelregierung. Mit Blick auf den Bundeshaushalt fordert er weitere Einsparungen.
------------------------------
Most similar news to news 1: 3 7 3
Ermittlungen: Mann wird auf Straße gefunden - und stirbt zwei Tage später
Ampelstreit: Christian Lindner fordert Kehrtwende in Wirtschafts- und Finanzpolitik
Der Bundesfinanzminister distanziert sich in einem Grundsatzpapier in Teilen von der Ampelregierung. Mit Blick auf den Bundeshaushalt fordert er weitere Einsparungen.
------------------------------
Most similar news to news 2: 14 14 14
Umfragen zur US-Wahl: Wer zieht ins Weiße Haus – Donald Trump oder Kamala Harris?
Die Kandidaten liegen weiter nah beisammen, doch Trump erlangt die Führung in wichtigen Swing-States. Die Daten zum US-Wahlkampf im täglich aktualisierten Überblick
US-Wahlkampf: Liz Cheney warnt nach erneuter Attacke vor Donald Trump
Auf offener Bühne diskutierte Donald Trump Gewaltfantasien gegen seine parteiinterne Kritikerin Liz Cheney. Die warnt nun vor einem Tyrannen als Präsidenten.
------------------------------
Most similar news to news 3: 11 10 11
Ampelstreit: Christian Lindner fordert Kehrtwende in Wirtschafts- und Finanzpolitik
Der Bundesfinanzminister distanziert sich in einem Grundsatzpapier in Teilen von der Ampelregierung. Mit Blick auf den Bundeshaushalt fordert er weitere Einsparungen.
Umgang mit der AfD: Senatorin warnt vor AfD-Verbotsverfahren auf Bundesebene
------------------------------
Most similar news to news 4: 11 11 11
3. Fußball-Liga: Wehen Wiesbaden mit Respekt vor Pokal-Schreck Bielefeld
Umgang mit der AfD: Senatorin warnt vor AfD-Verbotsverfahren auf Bundesebene
------------------------------
Most similar news to news 5: 10 10 10
Hochschulen: Peter Bernshausen ist neuer Kanzler der TU Chemnitz
Ukraine-Krieg: Der Winter naht, die Ukraine macht mobil
Die Ukraine erlebte im Oktober einen der härtesten Monate seit Kriegsbeginn. Jetzt beginnt der Winter. Wie ist die Stimmung? Und wieder Unwetterwarnungen in Spanien
------------------------------
Most similar news to news 6: 8 3 8
Katargate: EU-Staatsanwaltschaft ermittelt gegen hohen Beamten wegen Korruption
In der EU laufen Ermittlungen gegen Henrik Hololei. Der estnische EU-Beamte steht unter Verdacht, teure Geschenke aus Katar angenommen zu haben.
Nahostkonflikt: Trügerische Siege
Israel hat Irans Macht in der Region stark geschwächt. So dominant wie heute war es noch nie. Doch der Iran könnte aus seiner derzeitigen Schwäche eine Stärke machen.
------------------------------
Most similar news to news 7: 11 1 11
Zweithöchste Warnstufe: Unwetter erreicht Balearen: Starker Regen auf Mallorca
Umgang mit der AfD: Senatorin warnt vor AfD-Verbotsverfahren auf Bundesebene
------------------------------
Most similar news to news 8: 10 10 10
Nahostkonflikt: Trügerische Siege
Israel hat Irans Macht in der Region stark geschwächt. So dominant wie heute war es noch nie. Doch der Iran könnte aus seiner derzeitigen Schwäche eine Stärke machen.
Ukraine-Krieg: Der Winter naht, die Ukraine macht mobil
Die Ukraine erlebte im Oktober einen der härtesten Monate seit Kriegsbeginn. Jetzt beginnt der Winter. Wie ist die Stimmung? Und wieder Unwetterwarnungen in Spanien
------------------------------
Most similar news to news 9: 12 12 12
Kriminalität: 18-Jähriger soll mehr als 30 Straftaten begangen haben
Hamburgs Gewässer: Die Elbe kann mehr, als nur Schiffe zu tragen
Ein Podcast für mehr Lebensqualität: Hamburg könnte Elbe, Alster und Bille noch besser nutzen. Wo man künftig schwimmen, surfen und flanieren könnte.
------------------------------
Most similar news to news 10: 8 3 8
Ukraine-Krieg: Der Winter naht, die Ukraine macht mobil
Die Ukraine erlebte im Oktober einen der härtesten Monate seit Kriegsbeginn. Jetzt beginnt der Winter. Wie ist die Stimmung? Und wieder Unwetterwarnungen in Spanien
Nahostkonflikt: Trügerische Siege
Israel hat Irans Macht in der Region stark geschwächt. So dominant wie heute war es noch nie. Doch der Iran könnte aus seiner derzeitigen Schwäche eine Stärke machen.
------------------------------
Most similar news to news 11: 4 14 14
Umgang mit der AfD: Senatorin warnt vor AfD-Verbotsverfahren auf Bundesebene
US-Wahlkampf: Liz Cheney warnt nach erneuter Attacke vor Donald Trump
Auf offener Bühne diskutierte Donald Trump Gewaltfantasien gegen seine parteiinterne Kritikerin Liz Cheney. Die warnt nun vor einem Tyrannen als Präsidenten.
------------------------------
Most similar news to news 12: 9 9 9
Hamburgs Gewässer: Die Elbe kann mehr, als nur Schiffe zu tragen
Ein Podcast für mehr Lebensqualität: Hamburg könnte Elbe, Alster und Bille noch besser nutzen. Wo man künftig schwimmen, surfen und flanieren könnte.
Kriminalität: 18-Jähriger soll mehr als 30 Straftaten begangen haben
------------------------------
Most similar news to news 13: 0 3 3
Klimaschutz: Jugendliche sollen in Klimaräten mitwirken können
Ampelstreit: Christian Lindner fordert Kehrtwende in Wirtschafts- und Finanzpolitik
Der Bundesfinanzminister distanziert sich in einem Grundsatzpapier in Teilen von der Ampelregierung. Mit Blick auf den Bundeshaushalt fordert er weitere Einsparungen.
------------------------------
Most similar news to news 14: 11 2 2
US-Wahlkampf: Liz Cheney warnt nach erneuter Attacke vor Donald Trump
Auf offener Bühne diskutierte Donald Trump Gewaltfantasien gegen seine parteiinterne Kritikerin Liz Cheney. Die warnt nun vor einem Tyrannen als Präsidenten.
Umfragen zur US-Wahl: Wer zieht ins Weiße Haus – Donald Trump oder Kamala Harris?
Die Kandidaten liegen weiter nah beisammen, doch Trump erlangt die Führung in wichtigen Swing-States. Die Daten zum US-Wahlkampf im täglich aktualisierten Überblick
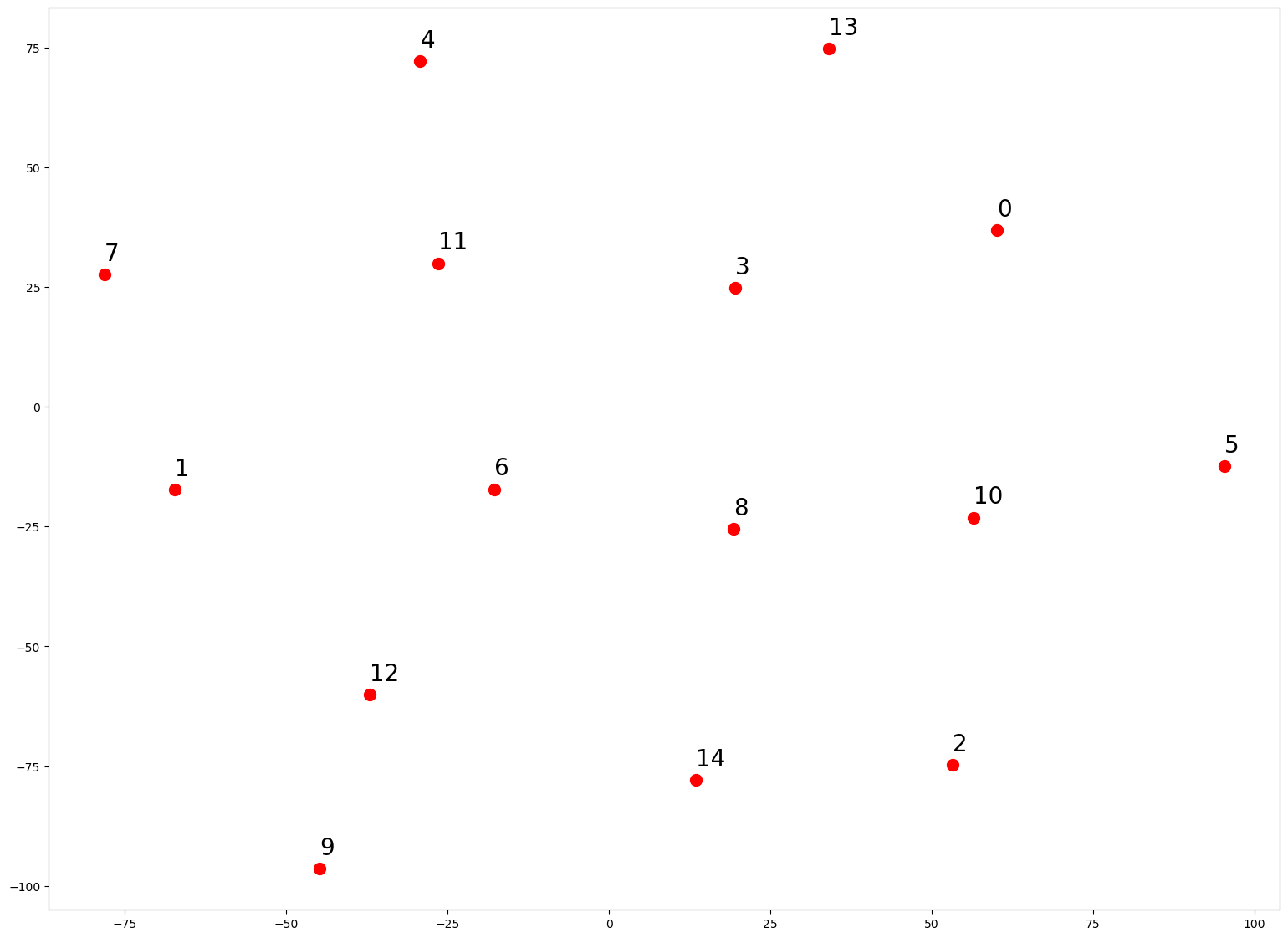
from sklearn.manifold import TSNE
from matplotlib import pyplot as plt
import numpy as np
tsneModel=TSNE(n_components=2,random_state=0,perplexity=12,metric="cosine")
np.set_printoptions(suppress=True)
model2d=tsneModel.fit_transform(bow_representation_idf)
plt.figure(figsize=(19,14))
idx=0
for a in model2d:
w=bow_representation_idf[idx]
plt.plot(a[0],a[1],'r.',markersize=20)
plt.text(a[0],a[1]+3,idx,size=20)
idx+=1
plt.show()