9. LLM Applications#
Basic Usage of LLMs
The basic usage of LLMs is depicted in the image below. The user’s query can be attached with some other context information. Query plus context information constitutes the prompt, which is passed to a LLM. The LLMs response should answer the users query. For applications like chatbots, the users query and the LLMs response is attached to the chat-history, which in turn is applied as context-information for future prompts.
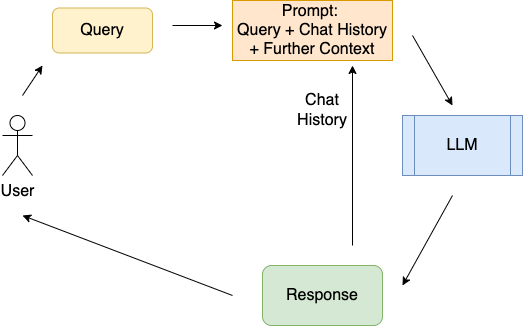
LLMs have shown impressive capabilities, however in their basic usage they suffer with problems like
hallucinations: Inaccurate or wrong responses, due to lack of corresponding training data
outdated knowledge: The necessary information is not contained in the LLM’s training data, e.g. for queries which are related to very recent events or to private knowledge.
non-transparent and untraceable reasoning: LLM does not provide information on its reasoning process.
Retrieval Augmented Generation (RAG)
Retrieval-Augmented Generation (RAG) is a promising approach to cope with the above mentioned problems of standalone LLM usage. RAG integrates the knowledge of external databases, with the LLMs knowledge. External databases
may keep very specific private data, e.g. on customers, products, projects, employees
can easily be updated (daily or hourly)
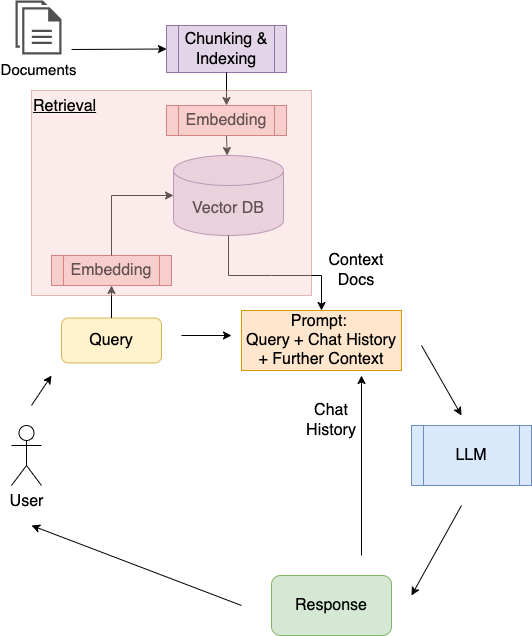
The basic RAG process is depicted in the following two images:
In a pre-retrieval stage
relevant external documents must be accessed
all external documents are chunked and indexed.
for each chunk an embedding (vector) is calculated
Embeddings are stored in the vector database.
In the retrieval stage
for the query of the user an embedding is calculated
then for the query-embedding the closest \(K\) embeddings in the vector database are determined
In a post-retrieval stage the retrieved documents may be post-processed, e.g. re-ranked.
In the generation stage the prompt (query + retrieved documents) is passed to the LLM, which generates its response.
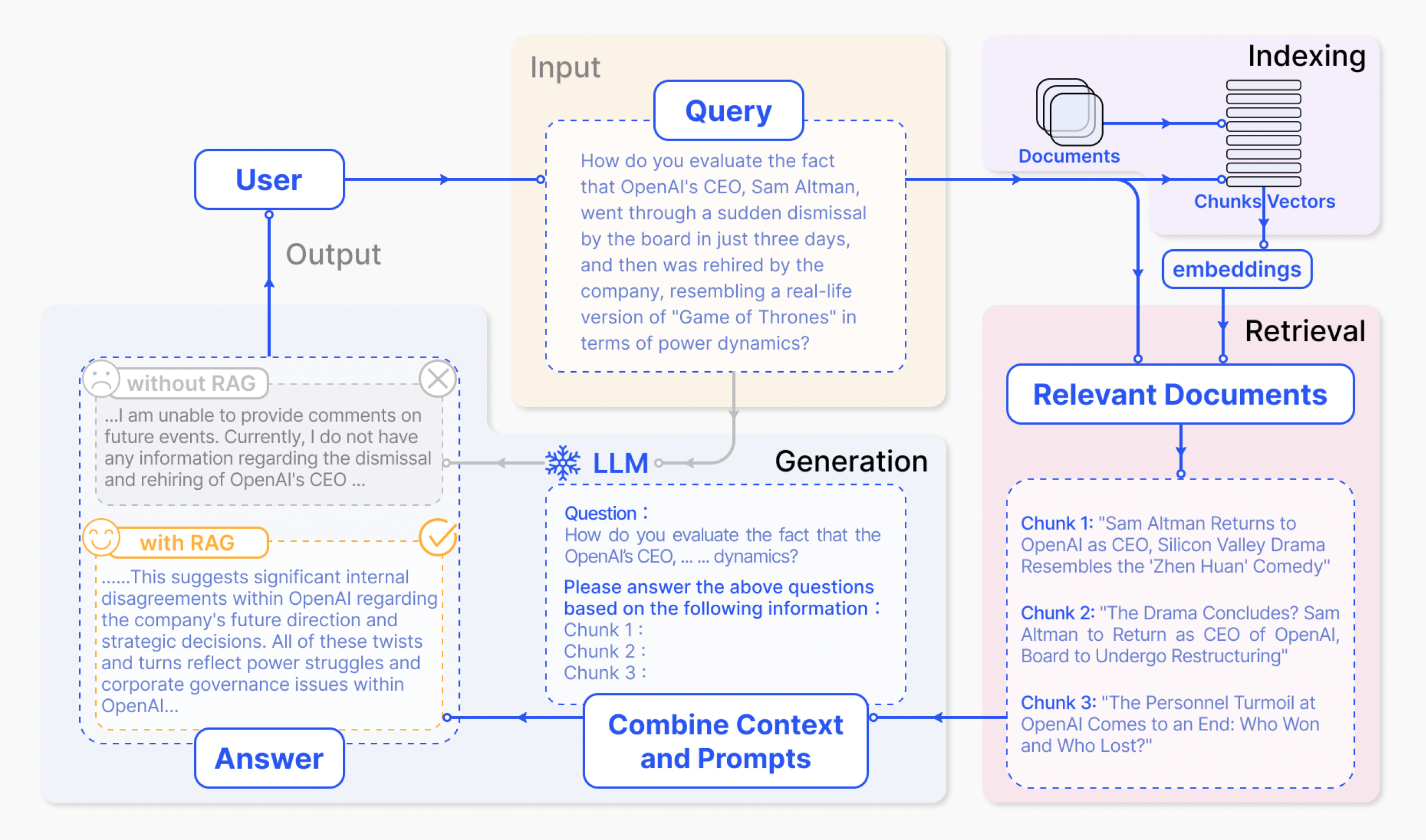
In the image below (Image source: [GXG+24]) an example of the basic RAG process is given.